一种es集群双机房高可用部署方法与流程
1.一种es集群双机房高可用部署方法,用于实现es集群双机房部署,属于计算机业务应用研发领域。
背景技术:
2.在日常的支付业务中,受监管、风险、成本等多维度因素影响,银行系统业务数据、日志数据需较长时间存储,且业务规则多变,使得统计分析数据变的更加困难,业务需要对历史数据进行统计分析,来开展创新业务。系统运维人员需要分析系统日志数据,来判定系统运维情况;上述分析多采用es集群来实现。
3.但现有的es集群大多数部署在同一机房,可满足一般要求的高可用性及数据安全,但面对金融行业苛刻的安全性、跨机房异地灾备的特性,传统的es集群部署方式则不能很好的满足。根据es集群本身特性,跨机房部署时在写入和查询数据效率会降低,无法应对高并发,低时延的检索需求。即部署在同机房,当机房数据发生丢失后(例如机房发生自然灾害),数据不能恢复,服务将会中断。若简单的将集群部署在异地双机房,集群数据写入和和查询效率将降低。
4.cn202010099024.2公开了一种双机房的容灾方法及装置,但存在如下技术问题:未体现数据备份完整性,即a机房数据全部丢失,数据是否能够恢复,即在一个机房完全损坏的情况下无法保证集群数据安全性、应用可用性及应用服务不中断;检测到某节点服务器出现故障,若对应主节点加入集群异常,高可用值得商榷,而无法使应用高可用得到保障。
技术实现要素:
5.针对上述研究的问题,本发明的目的在于提供一种es集群双机房高可用部署方法,解决现有技术中的集群部署无法保证集群数据安全性、应用可用性及应用服务不中断的问题。
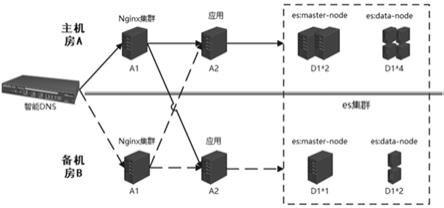
6.为了达到上述目的,本发明采用如下技术方案:一种es集群双机房高可用部署方法,包括:步骤1:将es集群安装部署在主机房a和备机房b,安装部署好后进行同一分片的副本分别分布在主机房a和备机房b、且分片和分片的副本位于不同区域的参数设置;步骤2:将nginx集群安装部署在主机房a和备机房b,并进行路由配置;步骤3:基于配置好的主机房a和备机房b实现高可用逻辑调用。
7.进一步,所述步骤1的具体步骤为:步骤1.1:在主机房a安装部署6台es节点,6台es节点为anode1
‑
anode6;步骤1.2:在备机房b安装部署3台es节点, 3台es节点为bnode1
‑
bnode3;步骤1.3:设置mater节点和数据节点:修改anode1、anode4和bnode1节点的配置,即将anode1、anode4和bnode1节点中的参数node.master设置为true,修改后,anode1、
anode4和bnode1节点为master节点;修改anode2、anode3、anode5、anode6、bnode2和bnode3节点的配置,即将anode2、anode3、anode5、anode6、bnode2和bnode3节点中的参数node.data设置为true,修改后,anode2、anode3、anode5、anode6、bnode2和bnode3节点为数据节点;步骤1.4:设置es集群按区域分配参数,即设置决定集群是否按区域分配的参数cluster.routing.allocation.awareness.attributes=zone,设置决定es集群强制划分区域的参数cluster.routing.allocation.awareness.force.zone.values=z1,z2,z3,以使一个区域只会保存同一shard的一个副本,且shard和副本位于不同区域,保证副本不会跨区域allocation,其中,shard表示es集群中用于存储数据的分片,每个分片有两个副本,allocation表示节点迁移;步骤1.5:设置es集群按区域分配参数后,为各节点划分编号:即设置各节点中的node.attr.zone参数,将anode1
‑
anode3节点的中的node.attr.zone设置为z1、anode4
‑
anode6节点的中的node.attr.zone设置为z2、bnode1
‑
bnode3节点的中的node.attr.zone设置为z3,其中,node.attr.zone表示区域划分编号参数,以将不同节点设置为相同的区域编号,实现将对应节点归属于同一区域。
8.步骤1.6:划分编号后,设置es集群至少需要两个master节点才能对外提供服务,并调整es集群发现其他节点的超时时间;步骤1.7:若主机房a和备机房b两机房间存在防火墙或者网络策略导致tcp在一定时间内中断,将主机房a和备机房b中各节点的参数network.tcp.keep.alive设置为true,通过此配置定时激活tcp通道,定时激活tcp的时间通过主机房a和备机房b中各节点的参数transport_schedule设置,其中,network.tcp.keep.alive表示定时激活tcp通道的参数,transport_schedule表示定时激活tcp的时间的参数。
9.进一步,所述步骤2的具体步骤为:步骤2.1:在主机房a和备机房b各部署一台nginx集群;步骤2.2:部署后,将主机房a和备机房b中的nginx集群的路由权重配置为2:1。
10.进一步,所述步骤3的具体为:基于配置好的主机房a和备机房b:当主机房a中的1个数据节点出现宕机情况:在主机房a的数据节点中抽取一个节点模拟宕机情况,即关掉抽取的节点或关掉抽取的节点所在的虚拟机,进行应用查询服务正常;当主机房a中两个区域各有一个节点出现宕机情况:抽取主机房a中两个不同区域的两个节点模拟宕机情况,即关掉抽取的节点或关掉抽取的节点所在的虚拟机,进行应用查询服务正常;当主机房a中有一区域的两个数据节点全宕机:在主机房a中任选一个区域的两台机器,模拟宕机情况,即关掉抽取的节点或关掉抽取的节点所在的虚拟机,进行应用查询服务正常;当三区域各有一数据节点出现宕机情况:在三个区域中,各抽取一台数据节点模拟宕机情况,即关掉抽取的节点或关掉抽取的节点所在的虚拟机,进行应用查询服务正常;当备机房b对应的区域中的数据节点全宕机:抽取备机房b的两台数据节点模拟宕
机情况,即关掉抽取的节点或关掉抽取的节点所在的虚拟机,进行应用查询服务正常;当区域z1中master节点出现宕机情况:抽取主机房a中的节点anode1宕机,即关掉抽取的节点或关掉抽取的节点所在的虚拟机,进行应用查询服务正常;当区域z2中master节点宕机情况:抽取主机房a中的节点anode4宕机,即关掉抽取的节点或关掉抽取的节点所在的虚拟机,进行应用查询服务正常;当区域z3中master节点宕机情况:将备机房b中的节点bnode1宕机,即关掉抽取的节点或关掉抽取的节点所在的虚拟机,进行应用查询服务正常;当备机房b中的节点全部宕机:抽取备机房b中的节点bnode1
‑
bnode3宕机,即关掉抽取的节点或关掉抽取的节点所在的虚拟机,进行应用查询服务正常;当主机房a中的节点全部宕机:主机房a全宕机导致master节点数量少于2,此时需要人工干预,判断数据重要还是业务重要,如需要提供服务,把备机房中的一个数据节点临时修改为mater节点,即将一个数据节点的node.master参数设置为true,否则,提供服务会报错。
11.本发明同现有技术相比,其有益效果表现在:1. 本发明中同一分片的副本分别分布在主机房a和备机房b两个机房,且分片和分片的副本位于不同区域,保证了数据的完整性和安全性;即保证了机房a/b因自然灾害等突发情况导致的a机房(主机房a)或者b机房(主机房b)节点全部宕机且数据丢失情况下,数据的可恢复性和完整性,即在保证查询效率的同时,兼顾数据异地存储,提高数据安全性;2. 本发明中nginx转发至服务的权重改为主机房a:备机房b=2:1,通过改变权重能把大约2/3的查询请求落在主机房a处理,能保证正常情况下集群的查询效率,因为集群部署是按照主、备机房2:1的比例部署;3. 基于本发明的部署和参数设置将es集群中各节点的参数index改为_routing.require=true,可根据路由机制查询,即根据存储文档id去指定分片查询,而不是遍历所有分片,具体为通过每条记录的doc_id路由查询,不需要对所有shards都查询一次,通过简单的配置,每次查询都会路由到一个shard或者它的副本节点上,可以避免每次查询必定跨机房的问题;4. 基于本发明的部署和设置,在查询时,可使用filter,避免打分,节约了耗时(即在不影响打分的情况下筛选出想要的数据),提高每一笔查询请求的响应时间;5. 本发明配置强制按区域分区cluster.routing.allocation.awareness.force.zone.values=z1,z2,z3,通过此参数可以保证主备机房(主机房a和备机房b)三个分片(其中,一个分片具有两个副本),同一副本不会落到同一区域的虚拟机节点上,以保证部分节点宕机时,不会在allocation(节点迁移)时影响性能,同时为了避免节点宕机,对应的shard(分片)会迁移至同一区域其它节点上(宕机节点上存储的shard会迁移至其他节点上),延长了"index.unassigned.node_left.delayed_timeout": "8h"迁移等待时间(即指es集群中某节点宕机后,延迟8h后才开始分配未分配的分片),在部分节点宕机后,管理员有足够时间恢复节点同时不影响在线服务;6.本发明引入es集群区域分区设置,后续通过查询路由设置及过滤打分机制设置,配合nginx设置路由权重,最大程度发挥集群优势满足高可用、高并发、低延迟的要求,极大程度地提升数据较检索效率、数据安全性,降低数据库使用成本。
附图说明
12.图1为本发明中es集群跨机房部署示意图。
具体实施方式
13.下面将结合附图及具体实施方式对本发明作进一步的描述。
14.一种es集群双机房高可用部署方法包括:步骤1:将es集群安装部署在主机房a和备机房b,安装部署好后进行同一分片的副本分别分布在主机房a和备机房b、且分片和分片的副本位于不同区域的参数设置;具体步骤为:步骤1.1:在主机房a安装部署6台es节点,6台es节点为anode1
‑
anode6;步骤1.2:在备机房b安装部署3台es节点, 3台es节点为bnode1
‑
bnode3;步骤1.3:设置mater节点和数据节点:修改anode1、anode4和bnode1节点的配置,即将anode1、anode4和bnode1节点中的参数node.master设置为true,修改后,anode1、anode4和bnode1节点为master节点;修改anode2、anode3、anode5、anode6、bnode2和bnode3节点的配置,即将anode2、anode3、anode5、anode6、bnode2和bnode3节点中的参数node.data设置为true,修改后,anode2、anode3、anode5、anode6、bnode2和bnode3节点为数据节点;步骤1.4:设置es集群按区域分配参数,即设置决定集群是否按区域分配的参数cluster.routing.allocation.awareness.attributes=zone,设置决定es集群强制划分区域的参数cluster.routing.allocation.awareness.force.zone.values=z1,z2,z3,以使一个区域只会保存同一shard的一个副本,且shard和副本位于不同区域,保证副本不会跨区域allocation,其中,shard表示es集群中用于存储数据的分片,每个分片有两个副本,allocation表示节点迁移;步骤1.5:设置es集群按区域分配参数后,为各节点划分编号:即设置各节点中的node.attr.zone参数,将anode1
‑
anode3节点的中的node.attr.zone设置为z1、anode4
‑
anode6节点的中的node.attr.zone设置为z2、bnode1
‑
bnode3节点的中的node.attr.zone设置为z3,其中,node.attr.zone表示区域划分编号参数,以将不同节点设置为相同的区域编号,实现将对应节点归属于同一区域。
15.步骤1.6:划分编号后,设置es集群至少需要两个master节点才能对外提供服务,并调整es集群发现其他节点的超时时间;步骤1.7:若主机房a和备机房b两机房间存在防火墙或者网络策略导致tcp在一定时间内中断,将主机房a和备机房b中各节点的参数network.tcp.keep.alive设置为true,通过此配置定时激活tcp通道,定时激活tcp的时间通过主机房a和备机房b中各节点的参数transport_schedule设置,其中,network.tcp.keep.alive表示定时激活tcp通道的参数,transport_schedule表示定时激活tcp的时间的参数。
16.步骤2:将nginx集群安装部署在主机房a和备机房b,并进行路由配置;具体步骤为:步骤2.1:在主机房a和备机房b各部署一台nginx集群;步骤2.2:部署后,将主机房a和备机房b中的nginx集群的路由权重配置为2:1。
17.步骤3:基于配置好的主机房a和备机房b实现高可用逻辑调用。
18.具体为:基于配置好的主机房a和备机房b:当主机房a中的1个数据节点出现宕机情况:在主机房a的数据节点中抽取一个节点模拟宕机情况,即关掉抽取的节点或关掉抽取的节点所在的虚拟机,进行应用查询服务正常;当主机房a中两个区域各有一个节点出现宕机情况:抽取主机房a中两个不同区域的两个节点模拟宕机情况,即关掉抽取的节点或关掉抽取的节点所在的虚拟机,进行应用查询服务正常;当主机房a中有一区域的两个数据节点全宕机:在主机房a中任选一个区域的两台机器,模拟宕机情况,即关掉抽取的节点或关掉抽取的节点所在的虚拟机,进行应用查询服务正常;当三区域各有一数据节点出现宕机情况:在三个区域中,各抽取一台数据节点模拟宕机情况,即关掉抽取的节点或关掉抽取的节点所在的虚拟机,进行应用查询服务正常;当备机房b对应的区域中的数据节点全宕机:抽取备机房b的两台数据节点模拟宕机情况,即关掉抽取的节点或关掉抽取的节点所在的虚拟机,进行应用查询服务正常;当区域z1中master节点出现宕机情况:抽取主机房a中的节点anode1宕机,即关掉抽取的节点或关掉抽取的节点所在的虚拟机,进行应用查询服务正常;当区域z2中master节点宕机情况:抽取主机房a中的节点anode4宕机,即关掉抽取的节点或关掉抽取的节点所在的虚拟机,进行应用查询服务正常;当区域z3中master节点宕机情况:将备机房b中的节点bnode1宕机,即关掉抽取的节点或关掉抽取的节点所在的虚拟机,进行应用查询服务正常;当备机房b中的节点全部宕机:抽取备机房b中的节点bnode1
‑
bnode3宕机,即关掉抽取的节点或关掉抽取的节点所在的虚拟机,进行应用查询服务正常;当主机房a中的节点全部宕机:主机房a全宕机导致master节点数量少于2,此时需要人工干预,判断数据重要还是业务重要,如需要提供服务,把备机房中的一个数据节点临时修改为mater节点,即将一个数据节点的node.master参数设置为true,否则,提供服务会报错。
实施例
19.步骤1:将es集群安装部署在主机房a和备机房b,安装部署好后进行参数设置;步骤1.1:在a机房中选择六台16c+32g的服务器,分别在六台服务器上安装es(即es节点),修改es配置文件elasticsearch.yml,将node.name依次设置为节点anode1
‑
anode6;步骤1.2:在b机房中选择三台16c+32g的服务器,分别在三台服务器上安装es(即es节点),修改es配置文件elasticsearch.yml,将node.name依次设置为节点bnode1
‑
bnode3;步骤1.3:将anode1、anode4和bnode1节点中的配置node.master置为true,node.data置为false,将anode2、anode3、anode5、anode6、bnode2和bnode3节点中的配置
node.master置为false,node.data置为true;步骤1.4:将anode1
‑
anode6、bnode1
‑
bnode3节点中的配置cluster.routing.allocation.awareness.attributes设置为zone。将参数cluster.routing.allocation.awareness.force.zone.values设置为z1,z2,z3。
20.步骤1.5:将anode1
‑
anode3节点中的配置node.attr.zone置为z1,anode4
‑
anode6节点中的配置node.attr.zone置为z2,bnode1
‑
bnode3节点中的node.attr.zone置为z3。
21.步骤1.6:将anode1
‑
anode6,bnode1
‑
bnode3节点中的配置discovery.zen.minimum_master_nodes置为2,即指es集群至少需要两个master节点才能正常提供服务。
22.步骤1.7:将anode1
‑
anode6、bnode1
‑
bnode3节点中的配置network.tcp.keep.alive设置为true,transport.ping_schedule设置为300s。
23.步骤2:在主机房a和备机房b中安装部署nginx集群。
24.步骤2.1:在主机房a和备机房b中各选择一台配置为2c+8g配置的服务器,安装nginx。
25.步骤2.2:修改nginx配置,在upstream中配置主机房a和备机房b两机房的应用请求路由地址,并将主机房a的路由地址权重设置为2,weight=2,备机房b的路由地址权重设置为1,weight=1。
26.步骤3:基于配置好的主机房a和备机房b实现高可用逻辑调用。
27.在主机房anode2、anode3、anode5、anode6四个数据节点中,任选一个数据节点,停掉该数据节点的es服务,验证应用查询服务正常。
28.将主机房a中数据节点anode2和anode5的es服务关停,验证应用查询服务正常。
29.将主机房a中数据节点anode5和anode6的es服务关停,验证应用查询服务正常。
30.将主机房a中数据节点anode2、anode6和备机房b中数据节点bnode2的es服务关停,验证查询服务查询服务正常。
31.将备机房b中数据节点bnode2和bnode3的es服务关停,验证应用查询服务正常。
32.将主机房a中master节点anode1的es服务关停,验证应用查询服务正常。
33.将主机房a中master节点anode4的es服务关停,验证应用查询服务正常。
34.将备机房b中master节点bnode1的es服务关停,验证应用查询服务正常。
35.将备机房b中bnode1、bnode2、bnode3的es服务关停,验证应用查询服务正常。
36.将主机房a中anode1
‑
anode6所有节点的es服务关停,备机房b机房中anode3节点的node.master置为true,验证应用查询服务正常。
37.基于上述各实现逻辑:验证网络抖动下集群工作状况。因跨机房部署需考虑不同机房间网络抖动情况,因此需要验证网络抖动下集群工作状况。
38.对主机房a中数据节点anode2进行设置:tc qdisc add dev eth0 root netem delay 50ms 20ms 50%(意思是将eth0网卡传输延迟设置为50ms,同时有50%的包会随机延迟30(50
‑
20)~70(50+20)ms),数据节点anode4设置tc qdisc add dev eth0 root netem loss 1%(意思是将eth0网卡的传输设置为随机丢掉1%的数据包),备机房b中数据节点bnode2设置tc qdisc add dev eth0 root netem delay 50ms 20ms 50%,验证应用查询服务正常。
39.将nginx路由至主机房a、备机房b应用地址权重设置为设置为2:1;将es集群中各节点的索引参数_routing.require置为true,对比设置前后应用查询服务的tps,设置后,应用查询服务的tps会显著提高;将es集群中索引查询时设置使用filter,对比设置前后应用查询服务的tps,设置了filter后,应用查询服务的tps会显著提高,同等条件下使用filter会比不使用filter的tps高;以上仅是本发明众多具体应用范围中的代表性实施例,对本发明的保护范围不构成任何限制。凡采用变换或是等效替换而形成的技术方案,均落在本发明权利保护范围之内。
完整全部详细技术资料下载
当前第1页 1 2 3
相关技术
- 多源遥感图像的融合方法与流程
- 嵌入式程序的程序更新方法、终...
- 区块链数据存储方法及装置、电...
- 一种地质体与结构体的自洽整合...
- 一种多建筑物的三维重建方法及...
- 彩色中央凹显示设备及其制造方...
- 人脸质量评估方法、装置及电子...
- 全链路交互式风控方法和系统与...
- 一种变电站虚拟实景仿真培训系...
- 一种大规模海上风电场的陆上并...
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1
漏洞扫描相关技术
- 异常请求的识别方法、系统、网络安全设备及服务器与流程
- 一种自动扫描手机支架的制造方法与工艺
- 一种扫描设备的制造方法与工艺
- 一种超轻量化的网络摄像头遮挡器的制造方法与工艺
- IP地址去重方法和装置与制造工艺
- 安全策略的生成方法及装置与制造工艺
- WEB漏洞检测方法、装置及系统与制造工艺
- 工控网络漏洞挖掘方法、装置及系统与制造工艺
- 一种设备安全漏洞的处理方法和装置与制造工艺
- 一种设备安全漏洞的处理方法和装置与制造工艺
网闸相关技术
- 一种计算机病毒过滤阀的制作方法与工艺
- 一种基于状态关系图的工控防火墙实现方法与流程
- 专网专用的网闸穿透安全方法与流程
- 一种用于加速工控防火墙规则匹配的方法与流程
- 媒体数据的处理方法及装置与流程
- 监控局域网中计算机的USB端口的方法及装置与流程
- 二维码加密传输方法及系统与流程
- 异常关机处理方法及装置、及配备该装置的电能计量设备与流程
- 一种防火墙与网闸相结合的网络隔离方法与流程
- 一种万能网络护照服务器的备份切换方法及系统与流程
es集群master节点数量相关技术
- 一种大规模集群数据库快速节点替换方法与流程
- 一种集群节点依赖包安装的方法、装置及系统与流程
- 一种自动部署Hadoop集群及伸缩工作节点的方法与流程
- 一种分布式集群服务结构及其节点协同方法与流程
- 一种批量集群节点管理方法、系统及计算机集群管理节点与流程
- 一种处理集群故障的方法及一种管理节点与流程
- LTE宽带集群多节点镜像组网的实现方法及装置与流程
- 一种集群中节点的调度方法及装置与流程
- 集群节点升级系统及方法与流程
- 用于确定接入节点集群的方法和装置与流程