爬虫对网盘文件下载

 小古伢
小古伢
 已于 2022-07-19 13:22:49 修改
已于 2022-07-19 13:22:49 修改
 阅读量922
阅读量922
 收藏
5
收藏
5


 点赞数
1
点赞数
1
目录
需求分析
1、网盘目录结构
2、大致分析一下包含的文件类型
3、分析文件如何下载
代码实现
1、伪代码编写
1.1、文件目录递归伪代码
1.2、文件下载伪代码
2、请求参数
2.1、目录获取的请求参数
2.2、文件下载的请求参数
3、代码实现
问题分析
前因
先说一下前因,女朋友刚接了一个尽调项目,客户发给了她一堆尽调材料,结果我一看,好家伙,东西还不少,而且更可气的是,这网盘禁止下载,网页右键都被禁用了,所以另存的路子也行不通。
女朋友问我,有没有办法下载下来?
我当然说有,毕竟...男人不能说自己不行!
下面分析一下需求开干!
需求分析
1、网盘目录结构
首先尽调材料包含两个目录
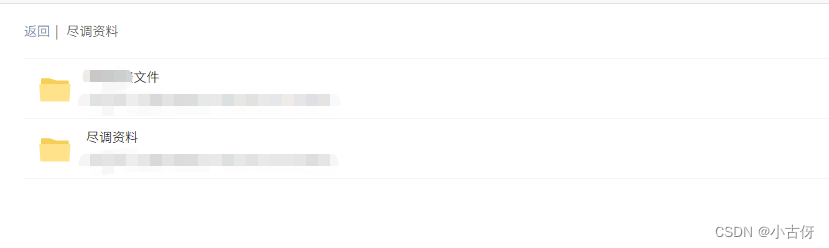
每级目录向下还有多级目录
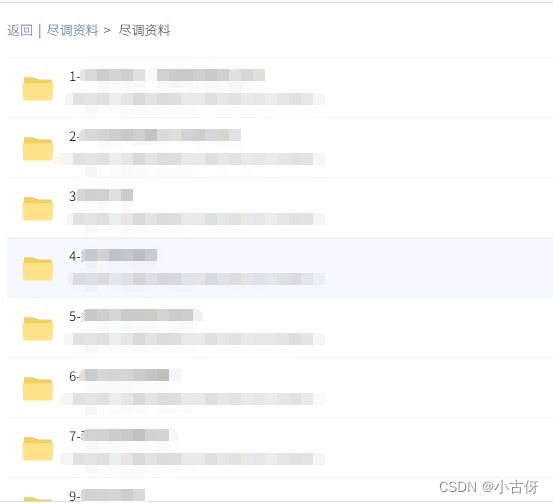
这个时候,如果我们想拿到所有的目录和目录文件,需要用到的最好的方式就是递归了。记下来,重点!!!
2、大致分析一下包含的文件类型
先随便打开几个目录,会看到存在最多的是.docx .xlsx .pdf和图片格式的文件,这基本上为我们写爬虫提供了有限的困难,因为类型越多,可能面临的爬取的困难就越大。
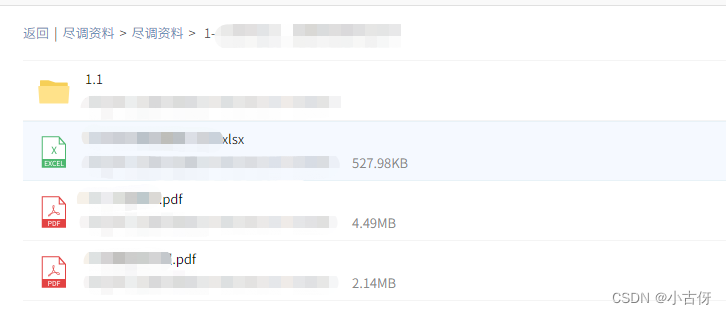
3、分析文件如何下载
我们首先随便打开一个文件,例如打开图片3第一个pdf,通过浏览器抓包工具分析该文件的实际地址。通过分析,可以看到可能有用的包为以下几个,我们逐个分析
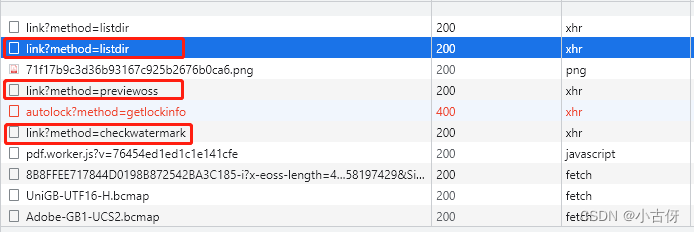
点开第一个listdir请求,查看返回值,会发现是一个json数据,返回的其实是图片3的目录结构,那第一个请求就PASS
接着再分析第二个请求,看到previewoss,基本就有种预感,这个和文件内容有关系。
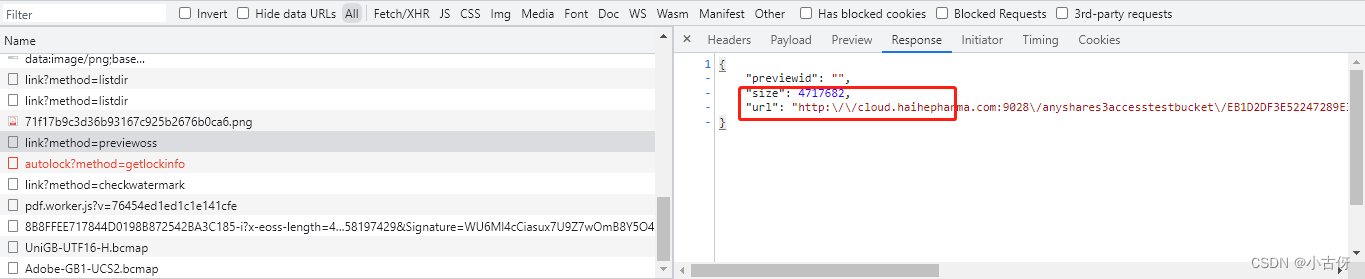
该请求同样返回的是一个json,键值包括size和url。那现在大胆猜测一下,这个就是文件真实的调用地址。或者我们可以计算一下size对应的文件大小是 4717682Bytes = 4.49Mb ,和图片3第一个pdf大小一致,进一步确定这里的url是对我们有用的,然后我们复制这个url粘贴到浏览器搜索框,发现下载下来了一个没有后缀名的文件。当我把这个文件添加上.pdf后缀后,可以正常打开,并显示和网页一致。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2157
2157










 暂无认证
暂无认证









 到【灌水乐园】发言
到【灌水乐园】发言










CSDN-Ada助手: Python入门 技能树或许可以帮到你:https://edu.csdn.net/skill/python?utm_source=AI_act_python