







TableStore是阿里云自研的在线数据平台,提供高可靠的存储,实时和丰富的查询功能,适用于结构化、半结构化的海量数据存储以及各种查询、分析。
爬虫数据特点
在众多大数据场景中,爬虫类型的数据非常适合存储在TableStore。主要是因为爬虫类型数据的一些特征和TableStore和匹配:
数据量大
爬虫数据一般都是抓取的互联网上的某个行业或领域的数据,数据规模和这个行业的数据规模有关,比如资讯类,每时每刻都在产生大量新闻报道,这个数据规模可能在10 TB到100 TB级别,如果考虑到历史存量数据,那么规模可能会更大。这么大量的数据存储已经不适合用单机的关系型数据库了,也不适合分库分表了,而需要一款分布式NoSQL数据库,这样可以将数据按一定的路由规则分布到不同机器上,实现自动的水平扩展,非常适合存储海量数据,尤其是爬虫类。
宽行和稀疏列
爬虫的数据一般来源于多个数据源,比如资讯数据可以来自人民网、新浪或者腾讯,每个数据源的数据特征不可能完全一样,每家有每家的特殊性,这样就会出现每一行数据的属性列有差异,虽然可以归一化处理后,可以将通用的属性列统一,但是不同数据源还是会存在一定差异性。如果为每个数据源建立一张表,那么工作量就会非常大,也不适合。这时候,就需要用到宽行和稀疏列功能,既能保证列数无上限,也能保证不同行不同列,还可以不额外增加存储成本和运维成本。
查询类型多样
爬虫数据的存储后,一般有两个出口,一个是数据处理程序,数据处理程序会读取最新的爬虫数据,然后按照自定义的处理逻辑做数据加工,处理完后会新数据写入原表或新表。
数据处理完之后,数据可以提供给下游企业客户或终端用户使用了,场景的查询需求有下列几种:
- 多种属性列组合查询。比如全网简历信息里面,通过年龄、学历、专长查询,且每个人查询的条件可能都完全不一样,需要多种属性列的自由组合查询。
- 分词查询。不管是咨询类,还是简历类,都有大量的文本描述,这部分内容都需要支持分词后再查询。
- 排序能力。比如资讯类数据中,查询某个新闻后,需要按时间逆序返回,越新的数据价值越大。
- 随机读能力。如果是用来做全局数据分析或处理,那么随机读是一种必须要有的能力。
- 轻量级统计分析。比如资讯类,想查看某个热点新闻的传播时间段和趋势,就需要统计每个时间段的此类新闻出现次数。
这些查询能力,在传统的关系型数据库或者开源NoSQL中都无法提供。
开源解决方案
爬虫数据存储的方案已经演进了将近二十年了,千奇百怪的各种方案都有,主要的差异来源于两点:
- 当前能获取到的存储系统能力。
- 自身对系统可靠性、可用性的要求高低。
我们下面以当前业界流行的开源系统为材料,打造一个爬虫数据存储的系统。
当前业内的开源存储系统有两大类,一类是开源的关系型数据库,比如MySQL等,一类是NoSQL,比如HBase等。这两类数据存储系统都不能支持分词查询,那么还需要一个全文检索的系统,当前可选的有solr和Elasticsearch。
基于上述的素材,我们就可以搭建一个存储爬虫的系统了:
- 首先,选择存储系统,MySQL和HBase都可以,如果使用MySQL,则需要分库分表,两者架构图差不多,这里我们就选择HBase。
- 再次,选择查询系统,可选的solr和Elasticsearch,虽然是同一类型系统,但是Elasticsearch的目前更流行,那我们也选择Elasticsearch。
这样,架构图大致如下:
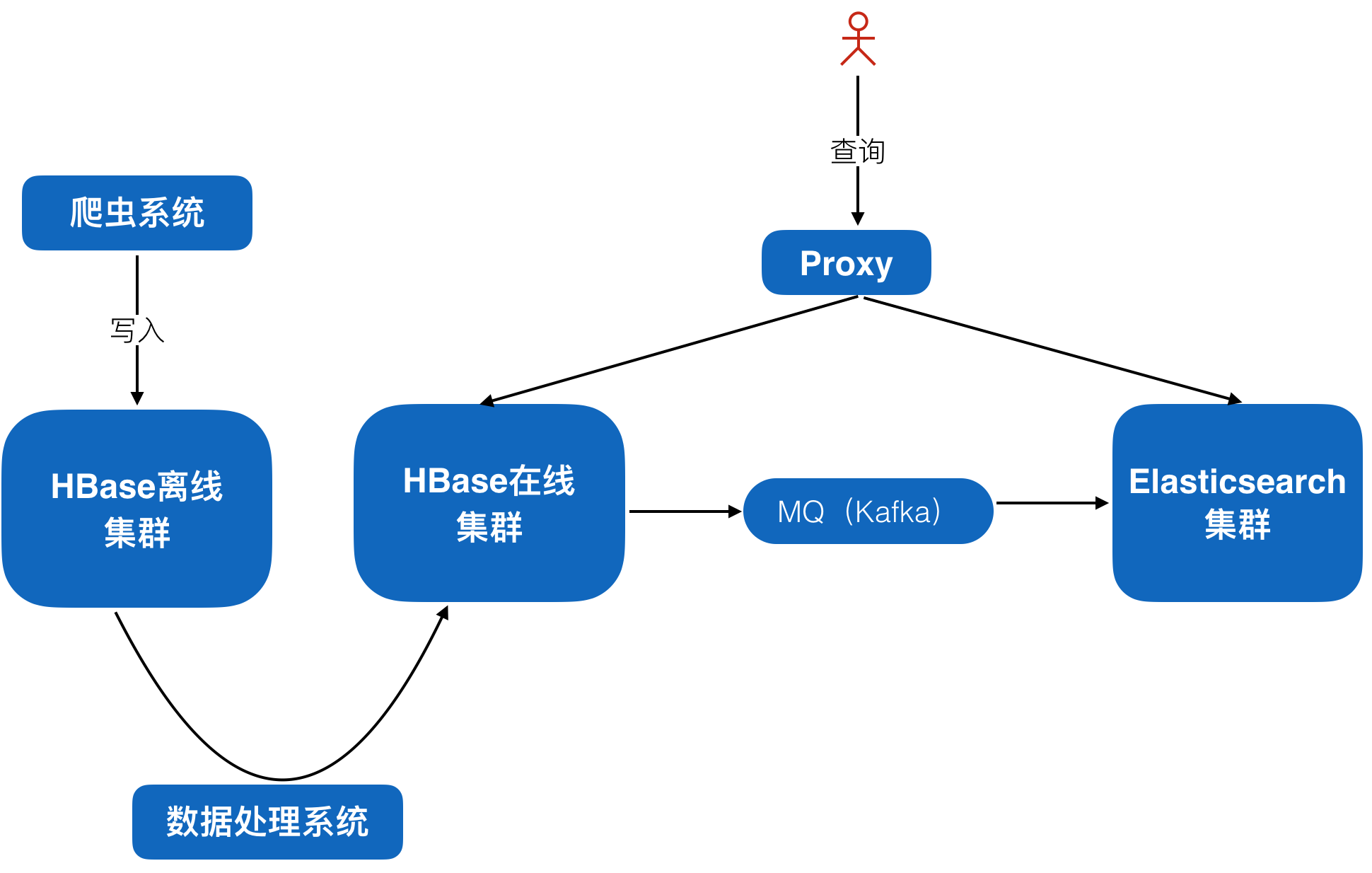
大概解释下:
- 流程:爬虫系统将抓取的数据写入HBase离线集群,然后数据处理系统周期性或流式的处理新到的数据,将处理后的结果写入HBase在线集群。HBase在线集群存储所有属性列的值,然后将需要查询的列通过co-processor发送给消息队列,最后再将消息队列中的数据被Elasticsearch消费,生成索引。最后,用户通过索引查询到PK,然后通过proxy到HBase在线集群读取这一行完整数据,最后返回给用户。
- 数据存储集群有两个,一个是在线集群,一个是离线集群,原因是为了避免减少离线集群对在线查询的影响,因为离线系统重吞吐,而在线系统重延迟,所以,这里会分成两个集群,目的是挺高系统可用性。
- 消息队列的目的是削峰填谷,减少对下游系统:Elasticsearch的压力,同时当Elasticsearch写入慢或者出故障后,不至于影响上游系统,目的也是为了提高系统可用性,避免单点故障导致整个系统雪崩。
- Proxy的目的是减轻客户端工作量,提高易用性的工具,原因是爬虫数据是系数列,这些列不可能全部都在Elasticsearch中创建索引,只有部分需要查询、分析的属性列才会在Elasticsearch中建立索引,但是查询的时候也需要未建立索引的字段,这样就需要一个系统做反查和合并,就是先查Elasticsearch获取到PK,然后通过PK到HBase在线集群查询这一行完整数据。
- 这个系统中,需要运维6个不同开源系统,运维压力比较大。
TableStore云解决方案
最开始,我们说TableStore很适合存储爬虫数据,在介绍了开源系统的解决方案后,我们再来看一下TableStore的解决方案,以及相对于开源系统,可以为客户带来的收益。
也先看一下架构图:
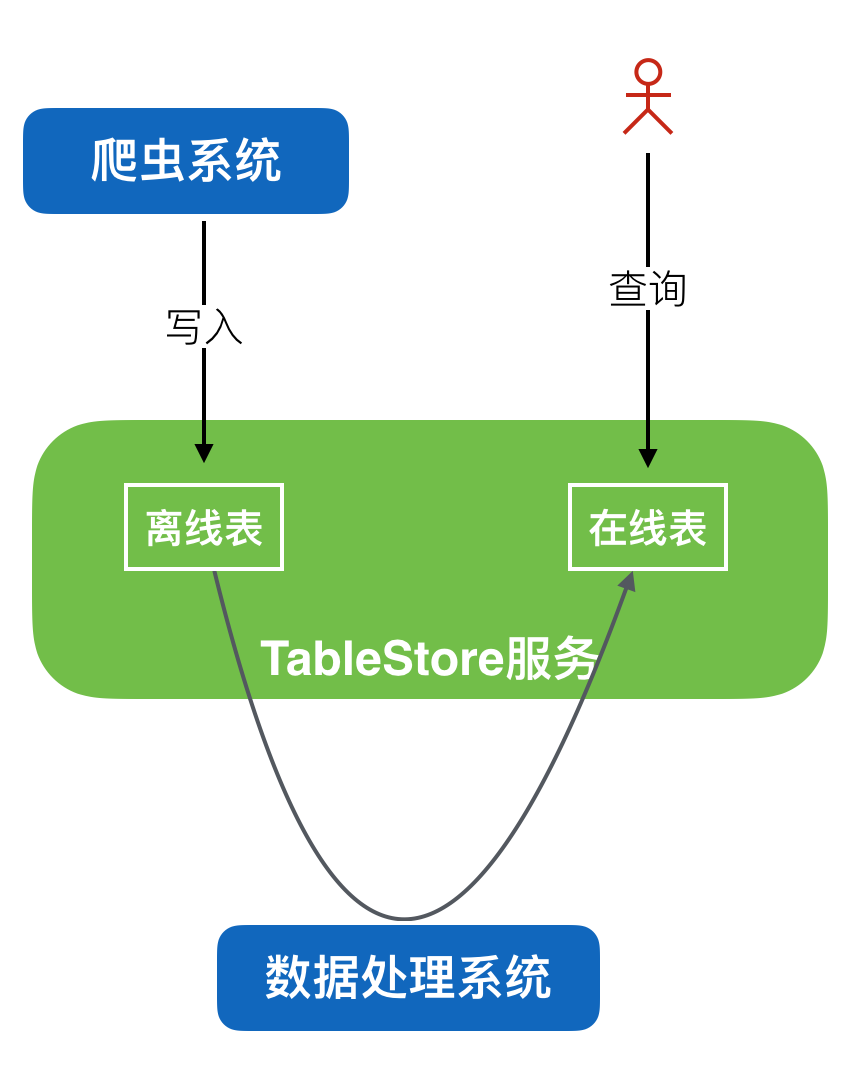
大概解释下:
- 爬虫系统抓取的数据写入TableStore的离线表,然后经过TunnelService的流式通道,数据进入数据处理系统做处理加工,再将加工后的数据写入在线表,用户直接查询在线表即可。
- 将离线表和在线表同时放在TableStore服务中,会不会出现离线表干扰在线表的情况?这个不会的,TableStore服务内部有自动的负载均衡和隔离系统,会自动处理这些问题。
- 所有的查询都可以直接查询在线表及其索引,提供了多字段组合查询、分词查询、排序和统计分析等功能,完全可以满足用户对查询的需求。
- 数据处理部分一般有两种处理方式,一种是离线全量处理,这种可以使用阿里云的MaxCompute系统,MaxCompute可以直读TableStore的数据做计算,不需要额外把数据导过去。另一种是流式实时处理,TableStore提供了 TunnelService系统,可以获取到实时的Table中的数据更新记录,然后将更新记录发送到函数计算、流式计算系统,或者自己的应用、flink等系统处理。
- 这个架构中,用户只需要运维2个系统即可。
示例
我们接下来举一个简历类爬虫数据存储和查询的示例,帮忙读者快速理解。
简历一般是一个PDF文档或者doc文档,是一个文件,但是我们可以从这些文件中抽取出结构化的信息,比如姓名、电话号码、身份证、邮箱、毕业学校、学历、专业领域、项目经验、兴趣、期望薪水和工作年限等。
首先,我们设计TableStore中主表结构:
| 主键列 | 属性列 | 属性列 | 属性列 | 属性列 | 属性列 | 属性列 | 属性列 | 属性列 | 属性列 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 身份证 | 姓名 | 电话号码 | 邮箱 | 毕业学校 | 学历 | 专业领域 | 项目经验 | 兴趣 | 期望薪水 | 工作年限 |
| String | String | String | String | String | String | String | String | String | Long | Double |
| 61xxx5 | 王一 | 152xxx7 | aa@xx.com | MIT | 硕士 | [数据库,MySQL] | 1.数据库binlog优化。 | [足球] | 20000 | 3.5 |
大概解释下:
- 主键列需要一个唯一值,用来唯一确定某个人,这里我们用了身份证,有些场景获取不到身份证,那可以用手机号或其他ID。
- 后面几个全部是属性列,包括姓名,电话号码等。期望薪水因为都是整数,所以可以选择Long类型,工作年限由于有小数,所以可以是Double类型。
- 通过这张表,我们可以通过身份证,查询到该用户的详细信息。但是无法通过属性列查询,如果需要通过属性列查询,则需要创建多元索引。
然后,我们再创建多元索引,多元索引的结构如下:
| 属性列 | 属性列 | 属性列 | 属性列 | 属性列 | 属性列 | 属性列 | 属性列 | 属性列 |
|---|---|---|---|---|---|---|---|---|
| 姓名 | 电话号码 | 毕业学校 | 学历 | 专业领域 | 项目经验 | 兴趣 | 期望薪水 | 工作年限 |
| Text:单字分词 | Keyword | Keyword | Keyword | Keyword Array | Text:多层语义 | Keyword Array | Long | Double |
解释下:
- 上面的多元索引结构中包括9列,比Table中少了2列,是因为不需要通过“邮箱”和“身份证”两个属性列查询,所以,在建立index的时候就不需要为这两列创建index了。但是如果业务中确实需要通过邮箱查询,那么多元索引创建时加上邮箱即可。
- 姓名的类型是Text:单字分词,意思是类型是Text,分词是单子分词,这样好处就是我可以通过搜索“小刚”搜索到“王小刚”、“冯小刚”等。
- 电话号码、毕业院校、学历都是Keyword类型(对应Table中的String),因为这些都字符串都比较短,且查询方式是直接完全匹配或者前缀查询,那么用String就可以了。
- 专业领域和项目经验两个属性列是Keyword Array的,因为是这两个属性列中会包括多个值,查询的时候只要有一个满足就可以返回,比如某个人的专业领域是:数据库、MySQL,那么我们查询“数据库”的时候,希望这个人返回。
- 期望薪水和工作年限是数字类型的Long和Double,这样这两个属性列就可以支持范围查找,比如查找工作年限大于2年,小于5年,且期望薪水小于2万的简历。
至此,我们就把简历库的table和index都建好了,用户就可以往Table中开始写数据,数据写入后会异步同步到Index中,这样就可以通过Index查询了。
总结
使用TableStore解决方案后,相对于开源解决方案,可以带来不少的收益:
减少运维负担
使用开源系统的架构中,需要运维6个系统,包括了3个开源系统:HBase、Kafka和Elasticsearch,为了运维这三个开源系统,需要有人对这三个系统比较熟悉,否则很难运维好。就算比较熟悉,也很难处理线上遇到的所有的问题,总会碰到无法解决的棘手问题而影响生产环境。
如果使用了TableStore云解决方案,那么就不需要运维任何开源系统,只需要运维自己开发的两个系统,同时关注TableStore中的两个表就可以了,这两张表的运维全部是TableStore服务负责,且提供SLA保障,绝对比自己运维开源系统的可用性要高。
同时,采用TableStore方案后,由于TableStore支持实时自动扩容,客户不再需要提前规划水位和集群容量,也不用担心高水位和突发流量对系统的冲击,将这些工作都交给了更擅长的云服务处理。
这样,不仅降低了运维的工作量和压力,同时也降低了系统风险,提高了系统整体的可用性。
减少时间成本
TableStore云架构方案相对于开源方案,系统更少,从零开始到上线需要的开发时间更少,同时,TableStore是serverless的云服务,全球多个区域即开即用,可以大大降低客户的开发上线的时间,提前将产品推出,抢先争取市场领先优势。
同时,TableStore支持按量付费,用户完全可以根据真实使用量付费,不再需要担心低峰期系统资源的浪费了,一定程度上,也能降低使用成本。
最后
目前,已经有不少行业的客户在使用TableStore存储爬虫数据,比如资讯类、生活类、文章类等等,也有部分用户在小数据量级时使用MySQL等关系型数据库,等数据规模大了后被迫迁移到TableStore存储。同时欢迎更多的客户开始使用TableStore存储你们的爬虫数据。
原文链接















 1305
1305










 暂无认证
暂无认证







 到【灌水乐园】发言
到【灌水乐园】发言










bitera: 怎么拿到签名的详细信息?有效期、是debug还是release
GoldenaArcher: 写的不错,活到老,学到老!欢迎回访我的博客
m0_52013371: 我现在是找不到那个文件和目录
m0_52013371: 解决不了咋办



Tisfy: 楼主的帖子实在是写得太好了。